27 Jun 202510 minute read

27 Jun 202510 minute read
This month, we hosted the first AI Native Dev meetup in London, with our friends from Codurance. We had some great discussions about AI Native Development at the event, with a couple of talks, one of which was given by me. During the session, I talked about the comparison of code-centric and spec-centric software development, which resonated with the audience. I was recently asked if there was a blog post on this topic, and I was surprised I hadn’t written one yet, so here it is!
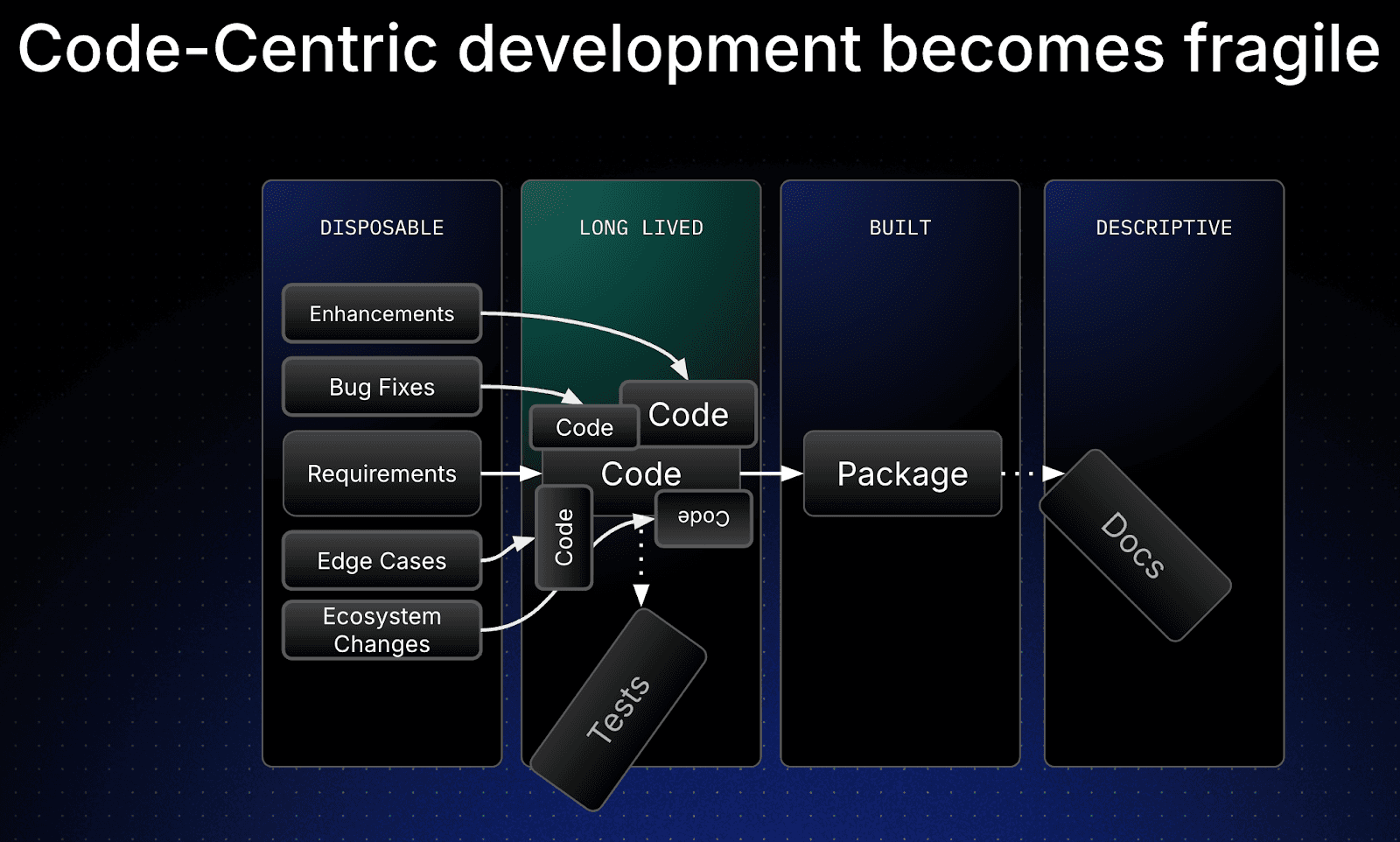
In today’s reality, we use a code-centric approach to software development. During the creation of an application, we typically start with a requirements doc, or a PRD that describes the intent of the application. From this document, or set of documents, we write our code in our language of choice. I’m not here to judge, unless your choice is PHP. The next stage is to get some tests (ok, I can hear TDD fanatics sigh. You pick your own order!) and make sure our code is working as intended before building and packaging our code up to ship. Oh, don’t forget those docs, too. Take a look at the slide I used to talk through this, and the words used to describe each of the artefacts.

The requirements are marked as disposable, as over time, they tend not to keep up with the latest version of the code. The code however, is long-lived, because it’s the source of truth. It’s what is changed and updated, and shipped. So if there's an issue in production, the code holds the answers, not the out-of-date requirements docs. The reason tends to be due to the way we evolve our codebase, by making:
We know the reality is that these changes are made in our codebase and rarely reflected back into the requirements docs. We’ve now lost the connection between our intent (the what) and our implementation (the how). Very often, the tests and docs also start to fall out of sync, as code updates aren’t reflected with updated or new tests, and docs become stale as they become out of date without strong development processes and diligent developers. Oh, and I know you’re diligent, it’s all the others out there that aren’t.
This results in a very fragile application with blurred lines between the what and the how, which now both reside in the code, which we often can only work out if we are able to talk with some of the original authors and maintainers of the code. This is, of course, subject to them still being available or a part of the org that created the code, and their ability to remember what happened. If their memory is anything like mine, good luck with that. We end up with the same old maintenance problems that we’ve unfortunately grown all too used to.
The typical AI developer tools that are popular today, such as GitHub Copilot, Cursor, Windsurf etc, help us create code faster, and make changes. However, they’re essentially updating the code.
How about agentic tools? They pretty much all still focus on updating the code too. The code still ends up as the source of truth. We’re still code-centric and are accelerating the problem. Some parts are erased. This doesn’t really make the best use of AI in the software development process.
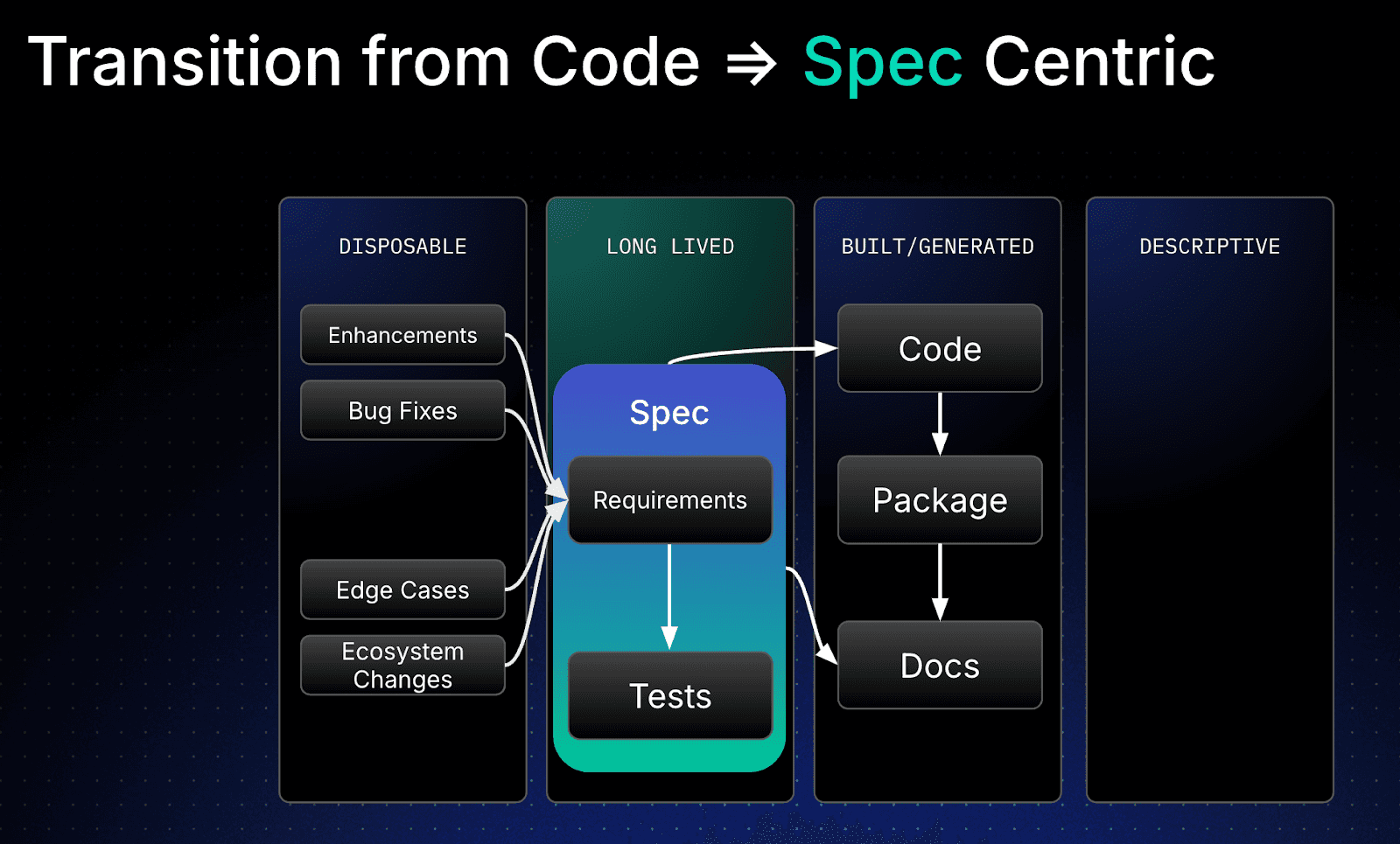
Let’s look at what happens when we make specs the new source of truth. In order to do this, the spec must be the primary artefact that the developer changes. It’s not a document that decorates or accompanies the code. It’s the document that the code is derived from at all times. If an enhancement or bug fix comes in, the spec is updated to reflect the change.
The spec should also contain the descriptions of the tests, because they also define intent. They state how the component should act, given various permutations of input and state. Using your favourite LLM, the code can now be generated from this complete spec, along with runnable tests, as well as documentation. Everything is in step and accurate to the specification. Here’s how the spec-centric approach looks, where the spec is now the long-lived artifact.
The benefits are pretty impressive as this becomes autonomous. I’ll mention a few here that are discussed on the slide below:
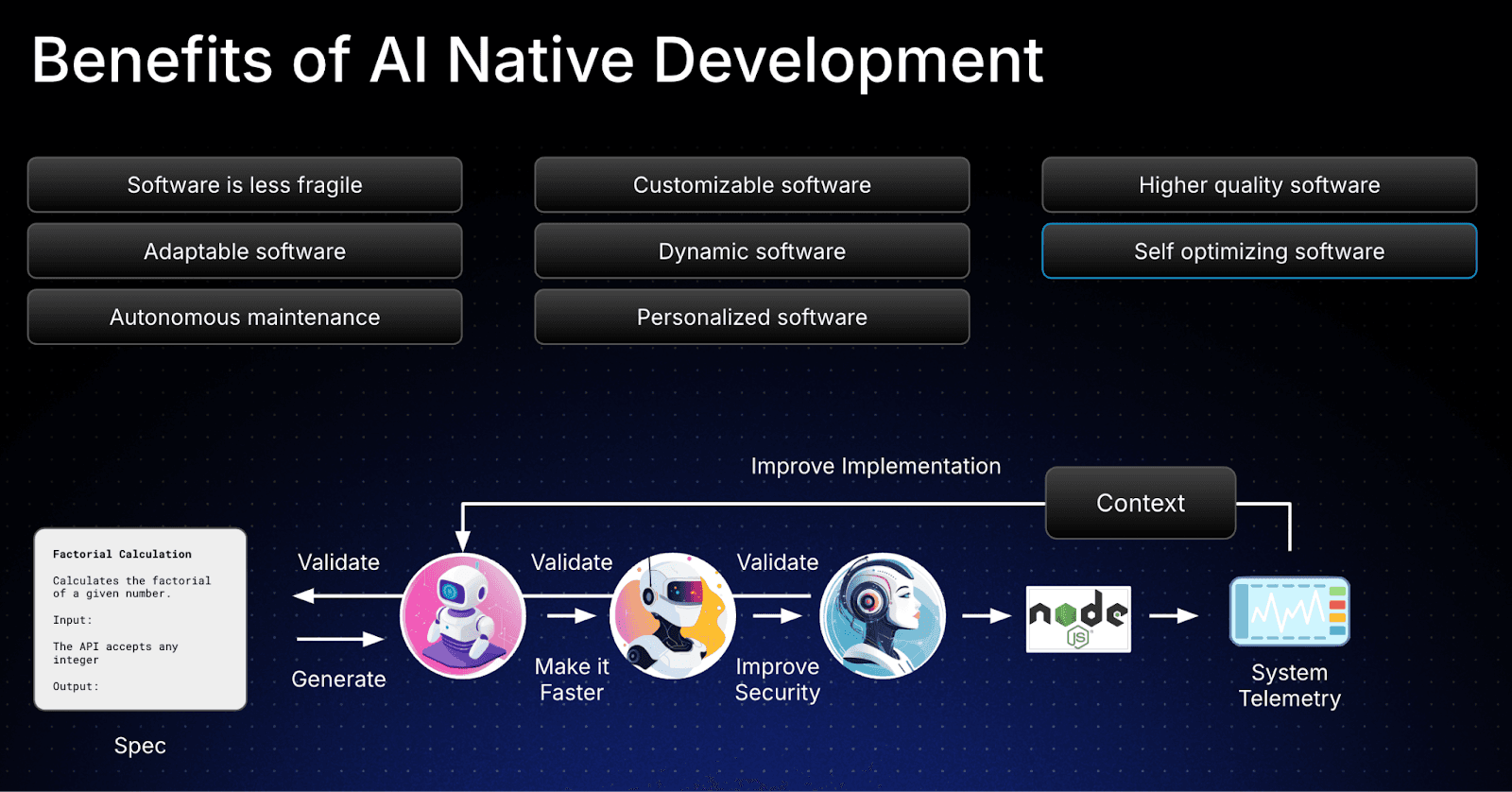
If this resonates with you and you can feel the value that spec-centric development can offer your software development workflows, i’d recommend watching the video either in it’s entirety, or just the bit I cover these slides. A couple of key things that stand out for me:
Join our community on Discord and subscribe to our mailing list to join our community to be a part of this movement and to contribute to answering some of these questions and many more!



