27 Nov 202519 minute read

27 Nov 202519 minute read
Benchmarks have long defined the tempo of technological progress. SPECint crowned CPU generations; ImageNet ushered in the deep-learning era. Now, as AI systems shift from predictive text engines to tool-using agents, a new class of benchmarks is emerging to measure how well these systems reason, act, and recover across complex workflows.
In the past month alone, there’s been a flurry of fresh benchmarks, spanning everything from long-horizon context management and enterprise-grade Java workflows, to cross-ecosystem developer tasks. This burst reflects just how quickly the agent landscape is expanding, and how urgently the field is searching for richer, more realistic ways to measure what these systems can actually do.
Here, AI Native Dev takes a look at some of the established and emerging benchmarks, exploring how, taken together, they hint at what a “perfect” AI agent might eventually look like.
Debuted back in 2023 by researchers from Princeton, SWE-Bench evaluates whether large language models (LLMs) – under a standardised, minimal agent scaffold – can resolve genuine GitHub issues by producing patches that pass a project’s test suite.
In the intervening years since launch, SWE-Bench has emerged as the go-to benchmark for assessing model-level coding competence in the real world, evolving into an open community project with broad industry support.
At the heart of the benchmark is a set of public leaderboards, split across categories such as Verified, Bash Only, Lite, Full, and Multimodal. Each tracks how well different models perform when constrained to specific interfaces or agent setups — from full-stack coding agents to minimal bash-only scaffolds. These leaderboards have become a running scorecard for the field, with labs routinely publishing new results as models improve. They offer a clear, comparable view of real engineering capability: not just which model can propose a patch, but which can do so reliably, efficiently, and under realistic development constraints.
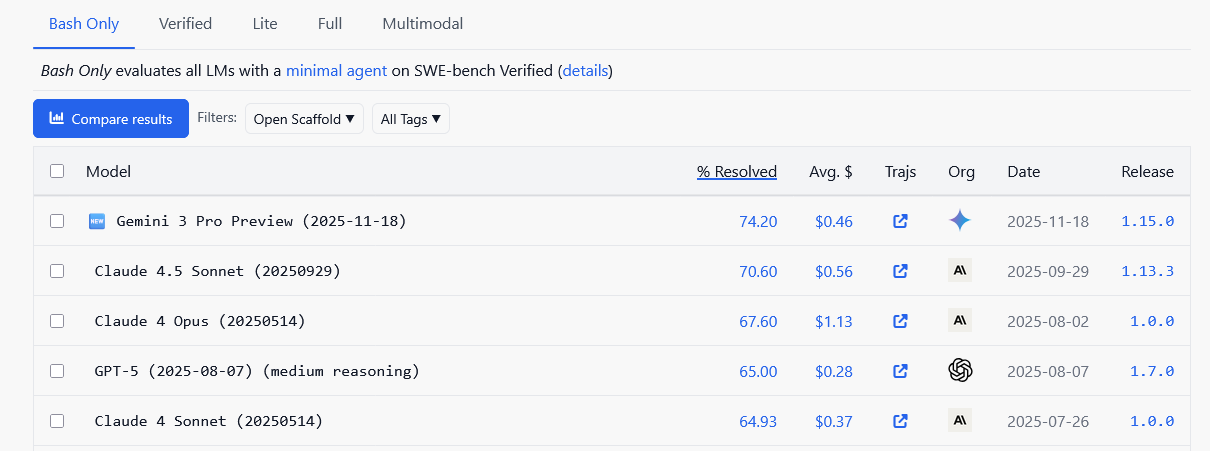
SWE-Bench has also spawned a number of specialised follow-on projects, including SWE-Bench Verified, which was developed in collaboration with OpenAI researchers, SWE-bench Bash Only, SWE-bench Multilingual, SWE-bench Multimodal, and SWE-Bench Lite. Collectively, these off-shoots broaden the evaluation surface — testing agents across different interfaces, languages, modalities, and levels of complexity.
It’s also worth noting that Amazon recently launched SWE-PolyBench, a complementary benchmark designed to evaluate how well models handle polyglot codebases spanning multiple programming languages — a capability increasingly relevant in large, heterogeneous software systems.
Launched in May, 2025 through a collaboration with Stanford and the Laude Institute, Terminal-Bench evaluates whether AI agents can operate inside a real, sandboxed command-line environment — the setting where much of practical software work actually happens. Unlike one-shot patch-generation benchmarks, Terminal-Bench measures an agent’s ability to plan, execute, and recover across multi-step workflows: compiling code, configuring environments, running tools, and navigating the filesystem under realistic constraints.
At the core of Terminal-Bench is its growing library of tasks — curated, real-world challenges contributed by researchers, engineers, and industry practitioners. These tasks span software engineering, system administration, scientific workflows, security, and even model training, each packaged with a natural-language description, a reference solution, and a verification script that judges whether the agent truly completed the job.
Terminal-Bench has become the leading test of agent-level operational behaviour, capturing a dimension that pure LLM evaluations tend to miss. Its leaderboard reflects this shift, ranking full agent systems — not just underlying models — based on their reliability across a suite of shell-based tasks. Categories such as Setup, Debug, Build, and Execution track different facets of CLI proficiency, creating a more holistic picture of end-to-end agent capability.
Terminal-Bench also underpins several research agents built specifically for tool-use and system-level execution, and has influenced the design of new agent frameworks optimised for robustness outside the comfort of text-only reasoning. Taken together, it fills a crucial gap in the benchmarking landscape: assessing whether an agent can actually do things, not just talk about them.
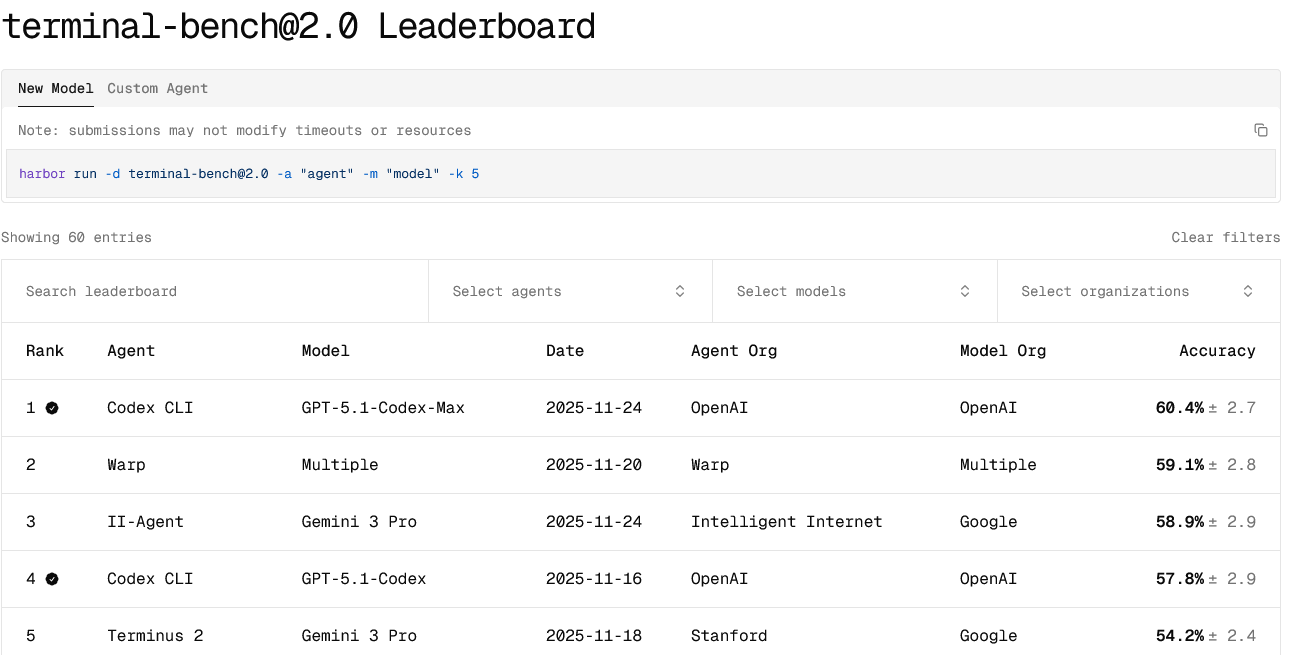
Debuted by conversation AI company Sierra in June, 2024, τ-Bench evaluates how well agent systems handle long-horizon, tool-enabled conversational workflows under realistic human-in-the-loop conditions.
The benchmark’s design emphasises three core criteria: (1) the agent must interact with both simulated human users and programmatic APIs across multiple exchanges; (2) it must follow domain-specific policies or rules (e.g. compliance or business logic); and (3) it must maintain high reliability at scale — repeatedly solving the same task across different trials with consistent outcomes.
In practice, tasks range from airline, retail, and (as of June this year) telecom scenarios, where the agent must ask questions, consult databases, invoke APIs and abide by policy documents. The evaluation introduces a “pass^k” metric to measure reliability over multiple runs: while some agents reach acceptable performance on a single trial, their success rate drops markedly when re-run with variation.
By capturing both reasoning + tool-use + policy adherence + repeatability, τ-Bench fills a gap in the agent-benchmark landscape: many other suites test one-shot outcomes, but don’t measure sustained interaction, policy compliance or reliability over repeated trials. It has become a go-to reference for evaluating conversational, tool-driven agents in production-adjacent contexts.
Introduced in October 2025 by Letta, a generative AI startup that spun out of UC Berkeley’s AI research lab last year, Context-Bench focuses on a capability that increasingly defines modern agent systems: the ability to maintain, reuse, and reason over long-running context.
Built on top of Letta’s open source evaluation framework, Context-Bench tests whether agents can chain file operations, trace relationships across project structures, and make consistent decisions over extended, multi-step workflows.
As context windows balloon into the millions of tokens and agents become more stateful, Context-Bench arrives at an opportune moment, offering one of the first structured ways to measure continuity, memory management, and long-horizon reasoning in agentic systems. Just as importantly, it exposes the cost side of these behaviours — something most agent benchmarks gloss over.
Early results show that strong performance on long-context tasks doesn’t always correlate with efficiency: some models achieve high continuity scores only by consuming dramatically more tokens, while others deliver comparable outcomes at a fraction of the cost. By surfacing this cost-to-performance ratio directly, Context-Bench promises a more realistic picture of agentic capability, helping developers judge not just whether a model can manage extended workflows, but how economically it does so.
While Context-Bench focuses on measuring raw context utilization, other approaches like Tessl's eval framework examine how structured context translates into practical task completion—offering a different lens on the same fundamental question of context value.
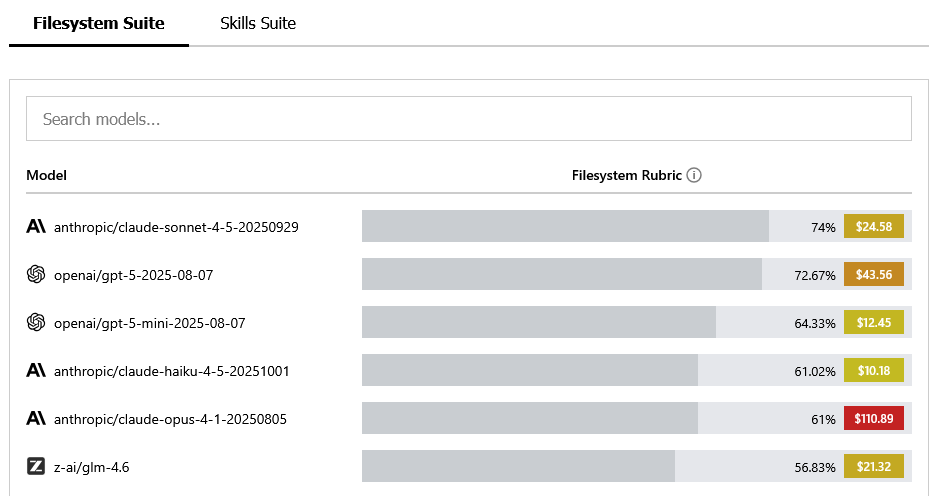
Also announced in October, 2025, Spring AI Bench is an open benchmarking suite for Java-centric AI developer agents. Where many agent evaluations focus on Python-heavy or framework-agnostic workflows, Spring AI Bench targets a domain often overlooked in mainstream agent benchmarking: the enterprise Java ecosystem.
Built around real Spring projects — the widely adopted, production-grade Java framework stewarded by VMware Tanzu — the benchmark evaluates how well agents navigate the conventions, build systems, and long-lived codebases that define enterprise software. It measures agent performance on tasks such as issue triage, dependency upgrades, PR reviews, compliance checks, and test expansion: the day-to-day maintenance work that keeps large-scale systems healthy.
Spring AI Bench’s value lies in its emphasis on enterprise realism. Unlike generalist coding benchmarks, it evaluates agents inside stable, opinionated frameworks with strict architectural patterns, rigid CI pipelines, and high bars for backward compatibility. Its leaderboard compares agent performance across repeatable, Spring-based testbeds, surfacing not just raw correctness but consistency under the constraints typical of enterprise development.
It’s still early days, and while full-scale public leaderboards are not yet broadly published, organisations and developers can already run the framework on their own codebases and track emerging comparative metrics.
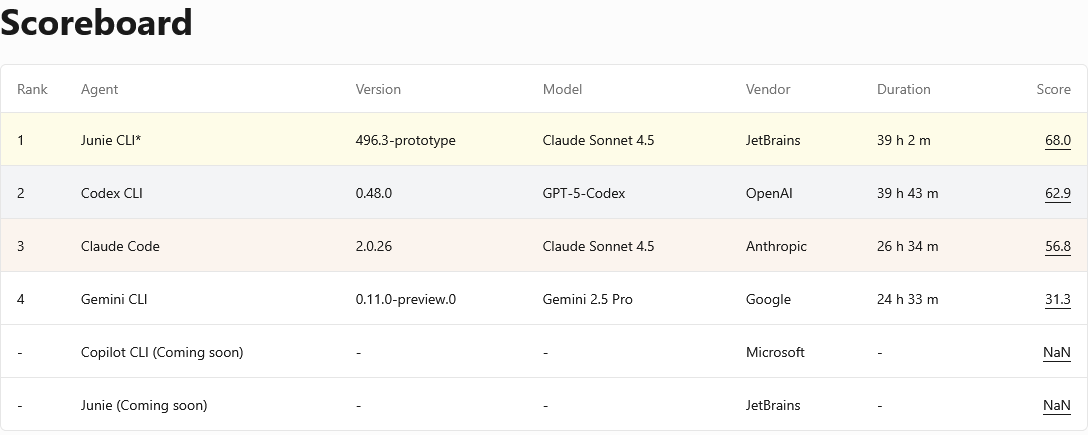
Launched in October 2025 by JetBrains, with plans to transition the project to the Linux Foundation, Developer Productivity AI Arena (DPAI Arena) positions itself as a broad platform for benchmarking coding agents across multiple languages and frameworks.
While the likes of SWE-Bench focus on issue-to-patch correctness, DPAI Arena evaluates full multi-workflow, multi-language developer agents across the entire engineering lifecycle.
Rather than focusing on a single task type, it evaluates a spectrum of developer responsibilities — patching, generating tests, reviewing pull requests, running static analysis, and navigating unfamiliar repositories.
Its design reflects JetBrains’ long-standing influence on developer tooling. The arena provides structured, reproducible environments modelled on the kinds of projects developers work in daily. Leaderboards rank agents not only by correctness but by workflow efficiency and behaviour across languages, offering a multi-dimensional view of developer-agent proficiency.
DPAI Arena’s ambition is to become a shared testing surface for the industry — a consistent, long-term framework where labs, enterprises, and open source projects can compare agent performance outside Python-only niches. If successful, it could evolve into the first truly cross-ecosystem benchmark for general-purpose coding agents.
Released in October 2024 by LogicStar AI, a startup developing autonomous bug-fixing systems, SWT-Bench shifts the focus from patch creation to another critical part of software engineering: automated testing. The benchmark evaluates whether agents can generate, repair, and execute test suites across real projects, capturing a capability essential for both quality assurance and self-correcting coding agents.
SWT-Bench tasks require navigating unfamiliar repositories, analysing existing test structures, and producing valid test cases that meaningfully cover the underlying code. Its leaderboard compares agents across categories such as Test Generation, Test Repair, and Coverage Improvement, providing insight into how well systems can reason about program behaviour rather than just source edits.
As testing becomes central to how agents validate their own work, SWT-Bench offers a timely measure of whether systems can participate in — or even automate — the feedback loops that underpin modern software development. Its focus on robustness and correctness complements patch-oriented benchmarks like SWE-Bench.
Introduced in November 2025 by the team behind Cline, an open source coding agent, Cline Bench aims to evaluate agents inside realistic, repository-based development environments. Rather than relying on synthetic prompts or contrived tasks, it converts real project snapshots and failure cases into reproducible evaluation scenarios, measuring whether agents can diagnose issues, navigate repo structures, and execute multi-step workflows reliably.
Because Cline Bench is built around authentic engineering work — real repos, real failures, real toolchains — the benchmark stresses practical agent behaviour: file edits, tool invocation, iterative refinement, and recovery after missteps. Comparable to Terminal-Bench in its emphasis on realistic, tool-driven execution but focused more narrowly on day-to-day development workflows, it offers insight into how agents behave when embedded directly in everyday coding environments.
It’s still early in its rollout: tasks are being curated, contributions are open, and early support has come from organisations and researchers interested in transparent, community-driven agent evaluation — but public leaderboards and widespread adoption are still in progress.
The benchmarks above focus on what agents can do — patch code, navigate terminals, execute multi-step workflows. But what about structured context — the information we give agents to work with? And how do we measure its impact?
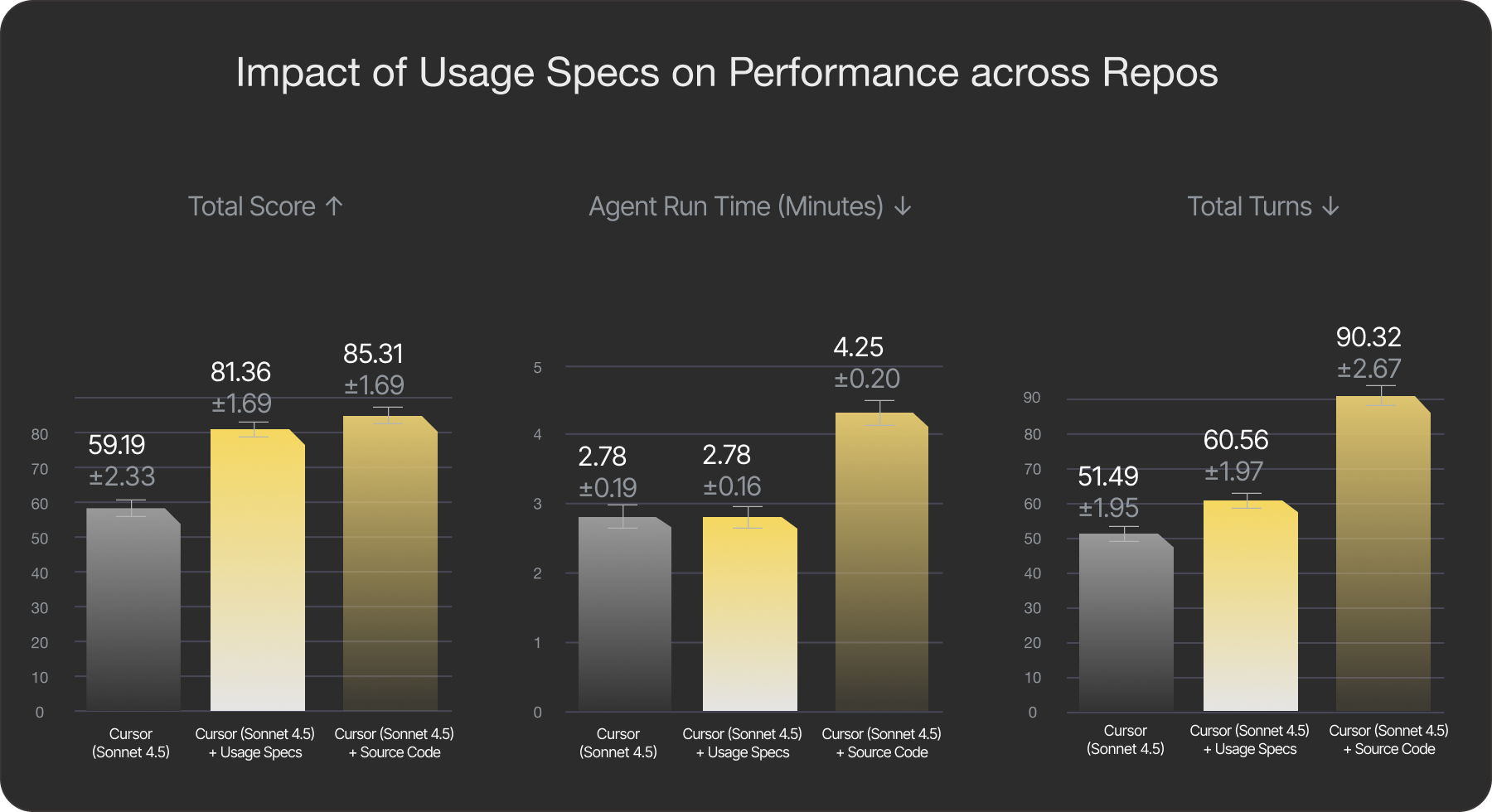
Tessl, an AI native development platform and sponsor of AI Native Dev, has been exploring this question through a proposed evaluation framework that measures the lift from providing structured specifications to agents. Rather than testing raw model capability, it isolates the effect of context quality: if you provide an agent with well-structured documentation, formatted for how agents actually consume information, how much more reliably does it perform?
Early results show specs improve proper API usage by approximately 35%. This matters because in real-world development, agents rarely fail due to lack of intelligence. They fail because they're missing context: hallucinating deprecated APIs, mixing up library versions, or applying patterns from one framework to another.
While all the aforementioned benchmarks above measure agent potential under controlled conditions, Tessl's evaluation framework focuses on agent effectiveness — the gap between what an agent can do and what it actually achieves when working in your codebase with the information you provide. A different lens, and a complementary one.
A quick peek across the broader evaluation landscape reveals a slew of additional new and emerging benchmarks such as GTA, CORE-Bench, MLR-Bench, Gosu Evals, and HAL, covering everything from general tool-use and scientific reproducibility, to cross-benchmark coding-agent evaluation and long-horizon robustness testing.
Collectively, this shows that no single benchmark captures the full spectrum of what a capable AI agent should do, with each focusing on a different axis of performance. While SWE-Bench measures real-world patch correctness and Terminal-Bench evaluates operational reliability in live tool-driven environments, others probe dimensions such as long-horizon context management, enterprise-grade workflows, test generation, and cross-ecosystem developer tasks. Each shines a light on a different piece of the agentic puzzle.
Taken together, these benchmarks show a field converging on a shared goal: agents that can not only reason, but act — consistently, safely, and across the messy, multi-step workflows real developers face every day.



