Learning #1 : AI Coding Agents are Truly everywhere
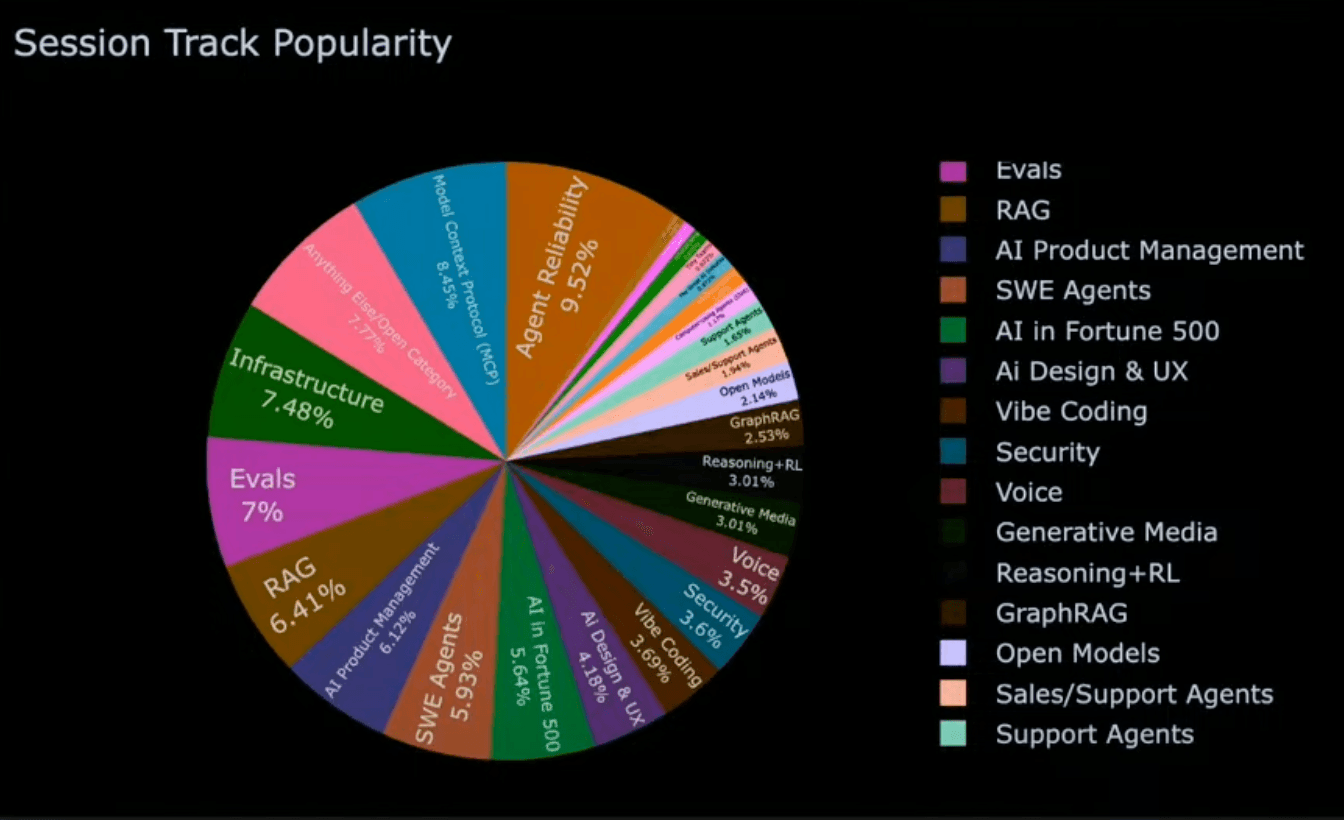
Being at its fourth edition, there is definitely a trend in AI coding becoming a topic on its own at the event. Obviously, the conference had the usual LLM models, RAG, graphRAG, and evals tracks, but this time it had a dedicated SWE-Agents track. It reflects the rising interest in coding with AI from the audience as presented by @swyx as well as the rising focus in the market as software engineering has shown itself to be a large success story for AI.
Every major AI coding tool was showcasing its new agent mode. They all bring their own narrative, but in essence, they all say autocompletion has been replaced with prompting, MCP tooling, and agents.
Learning #2 : Using AI Tools Like You Did 6 Months Ago Is a Mistake
Running agents also have an impact on coding interfaces. Some takeaways:
Sourcegraph Amp CTO Beyang Liu pointed out that the biggest mistake is using coding agents like you were 6 months ago. They now focus on simplicity and mentioned that, for example, they changed their default Enter behavior for prompts with line breaks to allow for longer agent instructions.
All Hands OpenHands engineer Robert Brennan mentioned that they adapted their agent from not submitting code as an agent identity, but on behalf of a user, to make sure there is ownership of code. This increased the interaction and efficiency of suggested changes.
Boris Chernyshowed how Anthropic is pushing Claude Code to headless, terminal-based coding tools running in the cloud.
Learning #3 - Specs are the new code
Code editors now pretty much have their own flavor of rules.md and allow you to add markdown files into a prompt. This removes the tedious typing in the prompt and allows you to build up a consistent set of requirements.
It was great to see Sean Grove, member of technical staff at OpenAI not only talk about ModelSpecs but also going all in on Specification Driven Development. The talk is chuck full of insights, here’s a brief summary from his talk “The new code: specs write once, run everywhere” (it’s a must watch!):
Prompting is sorta dead, in the next level you’ll be writing specifications
Prompts are ephemeral, the specs will persist
Specifications are a form of structured communication between humans and machines
Specs > Code: so much nuance and knowledge is lost just in the code
Writing them down makes specifications useful for LLMs but also aligns humans to agree upon them.
Tests are what makes specifications executable and verifiable.
With Agents moving to the cloud, there was also a rise in sandboxed execution vendors in the space. This is different from serverless execution systems as agents are typically longer running, can be suspended/resumed, and need streaming output.
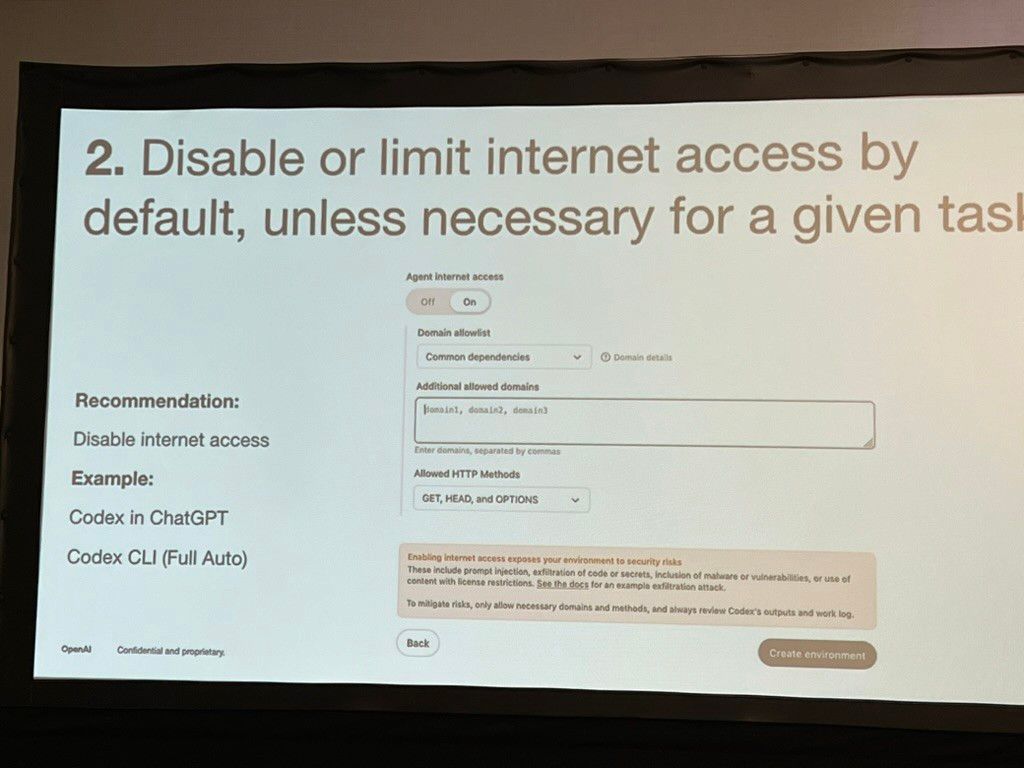
Much attention was given to the security issues from executing unvetted code and content and requiring rigorous permissions settings: Can it go out on the internet? What internal sources can it access? OpenAI Codex by default disables that access and allows you to set the right access levels.
Learning #5: Parallel execution means Parallel exploration
Going to the cloud solves the need for extra desktop horsepower:
In their workshop, Augment Code engineer Matt Ball showcased how they use this power to index larger and usually more legacy codebases, allowing for faster searches across different dependent codebases in one project.
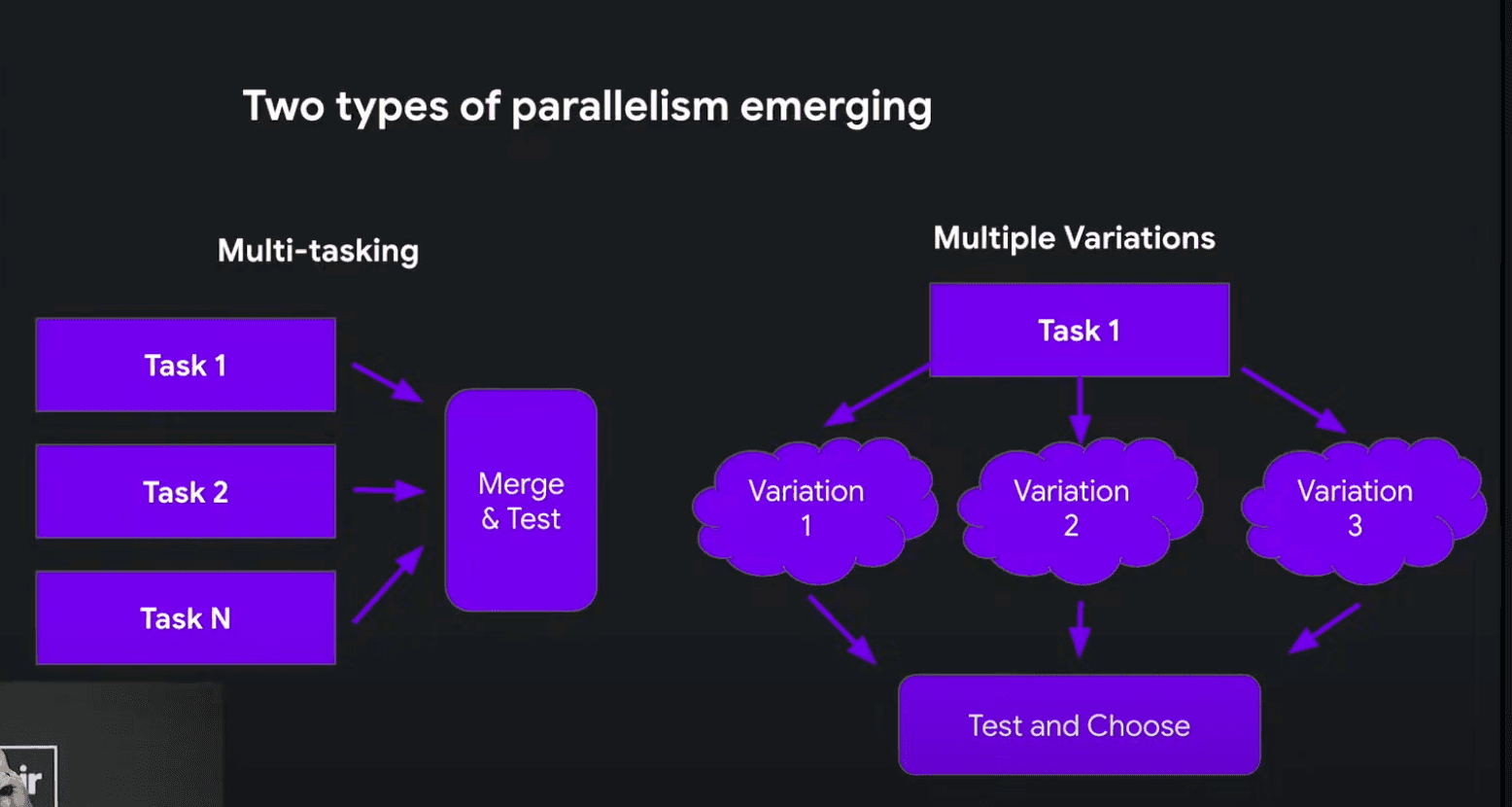
Jules code Product Manager Rustin Banksshowed that while many expect parallel execution to be about multi-tasking different agents working on the same codebase or subtasks, there is an emerging use case which is parallel exploration: just ask the agent to come up with different variations and you can judge which is the best one or and why not ask a LLM to be a judge too... or at least put in a vote for you?
Solomon Hykes CEO of Daggershowed how to do this parallelization and open-sourced container-use on stage: the tool hooks in your IDE as an MCP server and when you ask it for different variations, it spins up different containers in parallel. Each has their own git branch within their own isolated container. When you like the changes, you can merge the container git directly into the IDE git.
This matches the 3rd AI Native Dev pattern from Delivery to Discovery quite well: as execution and tokens get so cheap, we can explore different hypotheses.
Learning #6 - Is CI/CD shifting left?
With more and more code being produced, we’ll need better tooling for reviewing Pull Requests. Many AI Quality assurance tools were present as well:
Baz’s head of Product Shachar Azriel explained how they learn from PR comments and practices to build knowledge on what Developers think good looks like.
Graphite’s co-founder Tomas Reimers had some great insights that not all PR comments are equal: intersecting what bugs LLMs can catch with what comments developers want to hear 😅
Imblue’s CTO Josh Albrechtemphasized in his talk that the specs having strict guidelines also help in catching issues earlier in the value stream. Catching them at PR time is already more costly compared to catching them while coding. He referred to this as shifting left the testing of AI coding: If you think of the infinity DevOps loop, there is a closer agentic loop happening before the typical Test and QA running right in the developer’s IDE.
Learning #7 : How many X’s will AI deliver?
A common question around AI coding tools is how to measure their impact. While claims of 5x, 10x, or even 20x productivity gains are often seen on social media, many companies aren’t experiencing results anywhere near that. Why is that the case?
The task complexity: simpler tasks obviously benefit more from AI
Code base maturity: more mature codebases, which are more consistent, are less confusing for AI
Code base size: there is a maximum codebase size & context length complexity, topping performance for AI
Language popularity: popular languages benefit more from AI due to greater representation in training data.
Now these are technical factors, but don’t forget it also depends on your team and company technical maturity, as Fernando Cornago SVP at Adidas, points out in his ETLS talk.
Closing thoughts
What is considered good practice now can change really fast, and it’s hard to keep up. You might as well subscribe to our AI Native Dev newsletter or podcast.
The AI engineer summit is an amazing conference for content, think practical NeurIPS level
They attract the right practitioners and are very generous with their knowledge and content: a lot of tracks were livestreamed for free on youtube.
Even some of the talks that didn’t make it were selected to be on their online channel too.