1 Sept 202511 minute read

1 Sept 202511 minute read
| Plan | Cursor | Windsurf | Copilot (VS Code) |
|---|---|---|---|
| Free | 2-week trial; includes leading models | Infinite completions; 25 chat requests; includes leading models | 50 requests; leading models not included |
| Pro | $20 monthly → metered (≈$20 of API/agent usage). $200 tier gives ~20× usage across OpenAI/Claude/Gemini | $15 monthly → ≈500 prompts on leading models | $10 → 300 premium req (includes leadings models); $39 → 1500 premium req |
| Model Notes | Access to OpenAI/Claude/Gemini on higher tier | At test time, no major Anthropic models | Uses GitHub model routing; neat model comparison view |
I've prompted each tool to leverage this greenfield-spec.md (describing architecture, basic MERN stack scaffold) and then asked it to implement the spec, iterate, and adjust tests. In my observations, all specs produced by all three were very similar and all delivered working code.
On the UI/UX experience, Cursor felt the most professional in flow/explanations, but once refused to auto-build the project from spec. When it did build, it created a clean structure + tests and adjusted correctly as I changed the spec.
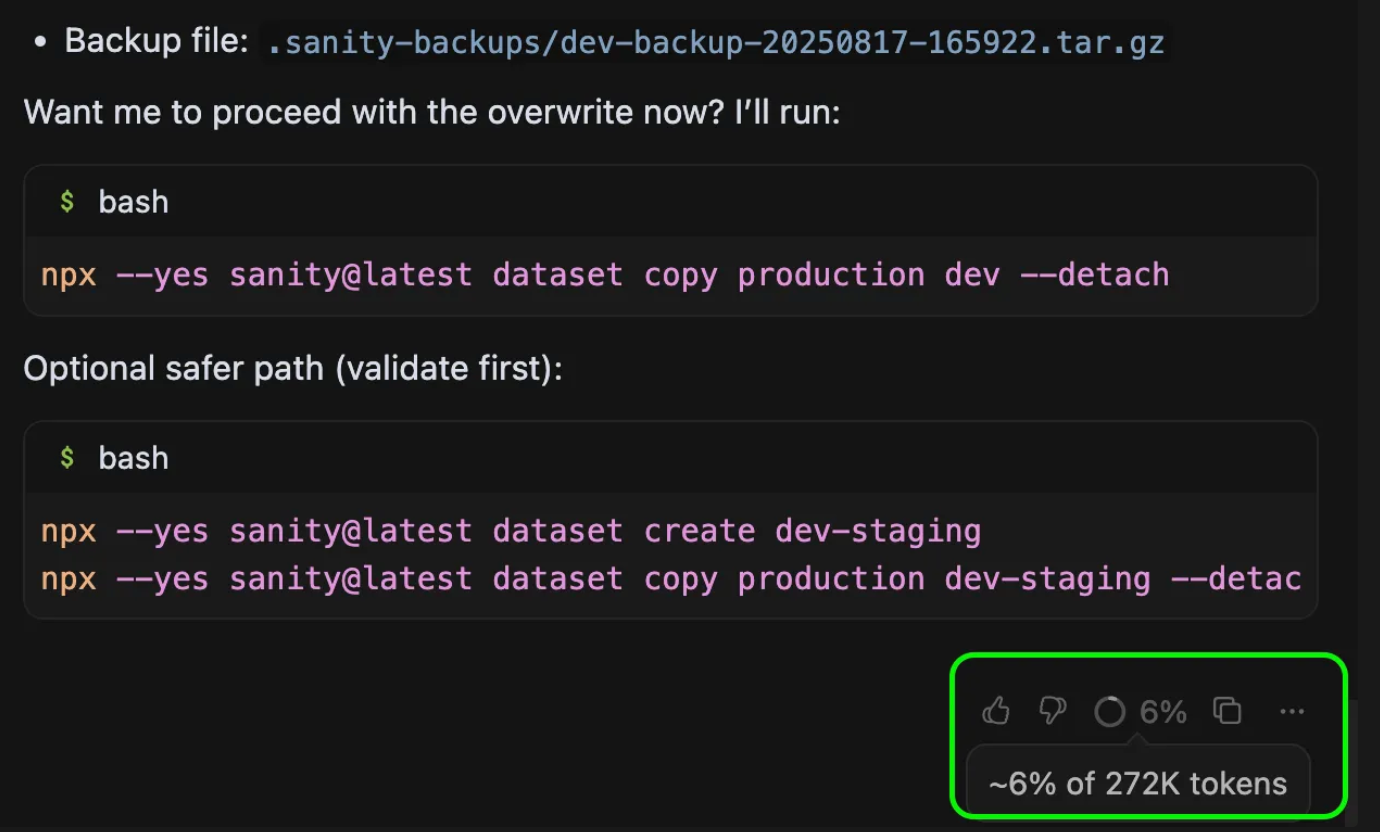
I also appreciated how Cursor usefully shows % of context consumed (~400k token total context with 272k input + 128k output). As for inline speed: Cursor ≈ Copilot > Windsurf. Though fast, Copilot's in-line refactoring fell short to Windsurf and Cursor's output.
When running the spec, Windsurf went full send. It created the whole project structure automatically (folders/files) without extra prompting. Windsurf's chat pane made it easy to distinguish model "thinking", command runs, and issues.
Copilot (VS Code) mostly showed file contents in chat with path hints, but didn't immediately write an on-disk tree. I did appreciate Copilot's in-IDE browser preview though, which was delightful for quick checks.
For testing, Windsurf and Cursor's generated tests passed on the first run in my sample. Copilot authored the strongest tests with granular mocking boundaries and edge case coverage. Though I had to wrestle a bit to get them passing, the self-contained modules made failures immediately traceable to specific component behaviors.
Getting started: Upon running locally, Copilot got the server up first, followed by Windsurf second and Cursor third - though notably, Cursor created a new .env.local instead of finding the right one, which slowed me down.
Codebase explanation: When it came to understanding the existing code, Windsurf explained the codebase exceptionally well, and the play on response format/highlights made it the best experience of the 3. That said, Cursor and Copilot were also able to read and explain legacy code effectively.
New feature (asked all to add a tool detail page + schema comparison across tools): All three successfully built from the brownfield-spec.md and produced sensible tests that ran well. This reinforced an important lesson: the clearer your spec, the more concrete the result.
Bug fix (subtle PostHog lazy-init bug): Here, Windsurf and Cursor diagnosed it faster, while Copilot missed it in my run. It's important to highlight that the bug comments were not added in the file (that would have been too easy ).
Refactor (scripted request across multiple files): All 3 executed the steps and staged changes properly, though with different approaches. Copilot required more approvals (e.g., 7 terminal prompts vs. Windsurf's 3 and Cursor's 1), which is great for caution but slower for flow. Interestingly, Copilot would sometimes say it's "been working on this problem for a while" and stall, whereas the others tended to keep iterating until done.
Overall, Windsurf > Cursor > Copilot for terminal/chat integration. Copilot runs commands outside the chat pane, which unfortunately breaks the narrative thread for me. Meanwhile, Cursor's default look and progress indicators feel the most cohesive, Windsurf communicates what's happening the best, and Copilot nails browser-in-IDE and markdown rendering.
On context and memory: Windsurf's "just remembers" feel is particularly strong for memory and context retention. Cursor gets there with rules/notes but will lose thread in long sessions, while Copilot keeps things simpler but consequently more ephemeral.
Notable touches:
grep); a restart fixed it → but it made me wonder: could this have been resolved without my intervention?"| Area | Cursor | Windsurf | Copilot (VS Code) |
|---|---|---|---|
| Greenfield build | Slick flow; solid structure + tests; once refused auto-build from spec; fastest inline suggestions | Auto-creates full project structure without asking; a tad slower inline; very clear terminal/steps UI | Shows file contents in chat (not a physical tree); browser panel inside IDE is great |
| Brownfield (legacy repo) | Explained codebase clearly; struggled with .env.local → server late to run | Strong codebase explainer; second to run server | First to run server locally |
| Tests | Good structure; passed on first try in my runs | Good; clear logs; steady | Strongest test focus, but took longer to make them pass initially |
| Agent behavior | Feels “aware” of when you want to build vs. converse; good multi-file edits | “Cascade” style workflow; keeps context/memory better; keeps working while you review | Tends to “do things” even for simple Q&A; more human-in-the-loop approvals |
| Context & memory | Explicit rules/files help; shows context usage % | Best seamless memory/continuity in practice | Session model simpler; starting a new chat ends current edit session |
| Chat/Terminal UI | Polished; good progress plan UI | Best separation of agent thoughts, commands, highlights | Terminal not inside chat; markdown paste turns into beautiful request formatting |
| Speed (inline) | Fastest | Slightly slower | Similar to Cursor |
| Frustrations | - | Inline could be faster | no possibility of multiple chats, no terminal in-chat, in-line sometimes struggles to capture intent |
| Neat bits | shows % of token limit; custom retrievals | Smart UI hints and file logos in chat; background work while you review | In-IDE browser; pretty markdown once pasted in request |
All three experiences ride on VS Code - Windsurf and Cursor are forks; Copilot runs inside VS Code. That means capability deltas may be subtle: same keyboards, similar models, similar APIs. The differentiation shows up in micro-interactions, like how the agent plans, how much it explains, how the terminal/chat loop flows, and how well the UI helps you stay oriented. If you're expecting a jaw-dropping, orders-of-magnitude difference, that wasn't my experience. In my opinion, the small product details and moments of delight are what choose your daily driver.
That said, I found that each IDE may come in use depending on your use case. This is a lightly opinionated take, not gospel:
It's important to note that this exercise comes with several limitations, including (and not limited to) the complexity of the builds, the tests coverage, the size of the codebase, etc. That's why I recommend experimenting with these tools yourself: you'll want to choose the one that best matches your (or your team's) needs.
Finally, the current status quo is only ephemeral. Each IDE may develop defensibility with how fast they ship their features. Cursor's own in-line edits as an example has been developed in-house, and was clearly felt throughout this experiment. It will be interesting to observe the pace of feature releases from these three tools. When I converse with engineers, the consensus leans toward Cursor demonstrating stronger execution capabilities, while Copilot appears to be slower in comparison. Meanwhile, given the recent tumultuous Windsurf acqui-hire and the accompanying leadership changes, we may see a shift in its release cadence.
Despite their capabilities, none of these IDEs fully embrace spec-driven development as a first-class citizen (unlike the recent release of Kiro).
While they can generate and work from specs, the workflow remains bolted-on rather than native - you're still manually adding your specs, losing track of which code implements which requirements, and lacking formal verification that implementations match specifications. Memory and context management, though improving, remains ad hoc across all three; they remember recent edits but struggle to maintain architectural decisions or cross-session constraints.
Test and mock generation quality varies wildly depending on how you prompt, with no systematic approach to coverage or edge cases. The gaps become even more glaring: no audit trails for AI-generated code changes, absent cost attribution per dev or project, and no integration with existing governance workflows.
These tools lack team-wide consistency enforcement - each developer's AI assistant learns different patterns, creating style drift across the codebase. There's no way to enforce company-specific architectural patterns, security requirements, or compliance rules at the AI level.
This points to non trivial opportunity for next-gen IDEs where specs aren't just documentation but executable contracts, where AI agents understand and preserve organizational standards, and where generated code comes with provenance and accountability. If you are interested in learning more about the interesting projects built around spec-driven development, you can search find them on the Landscape, the guide to the AI development ecosystem.



