Of all of the announcements at I/O, the one I am probably most excited about was quickly mentioned in the keynote, Gemini Diffusion:
Why am I so excited? It’s great to see models that use different techniques that can potentially dramatically change the speed of generation, while keeping the quality high, or even improve it for some cases. It’s early days, and we will see if this becomes real, but if so… it can be a game changer, with a different level of UX.
For the longest time, we used diffusion models for image generation, and autoregressive ones for text. Autoregressive models generate code token-by-token from left to right. This sequential process is accurate but somewhat inherently slow – each token requires a new inference step, and long code outputs may involve hundreds of steps.
Diffusion models, by contrast, generate via an iterative refinement process rather than one-step-at-a-time output. Instead of starting with an empty prompt and adding tokens sequentially, a diffusion language model starts from a “noise” representation of the output and refines the entire sequence in parallel over multiple rounds. Each iteration denoises or improves the whole sequence, gradually transforming gibberish into coherent output. Importantly, this allows diffusion models to generate whole blocks of tokens concurrently, offering potential speedups by using parallel computation across the sequence.
Google teased a text diffusion model that:

One of the other advantages of diffusion is that you aren’t stuck with past decisions in the same way that you are when you go token by token. Google highlighted how their model can error correct during the generation process, and how this approach can excel on tasks such as editing and filling in the middle. I am excited to see how it can help with use cases such as fixing bugs, and refactoring code, which seem nicely aligned.

Diffusion models for text are not new. You can read papers, and in February Inception Labs shared their Mercury Coder diffusion models, to much aplomb:
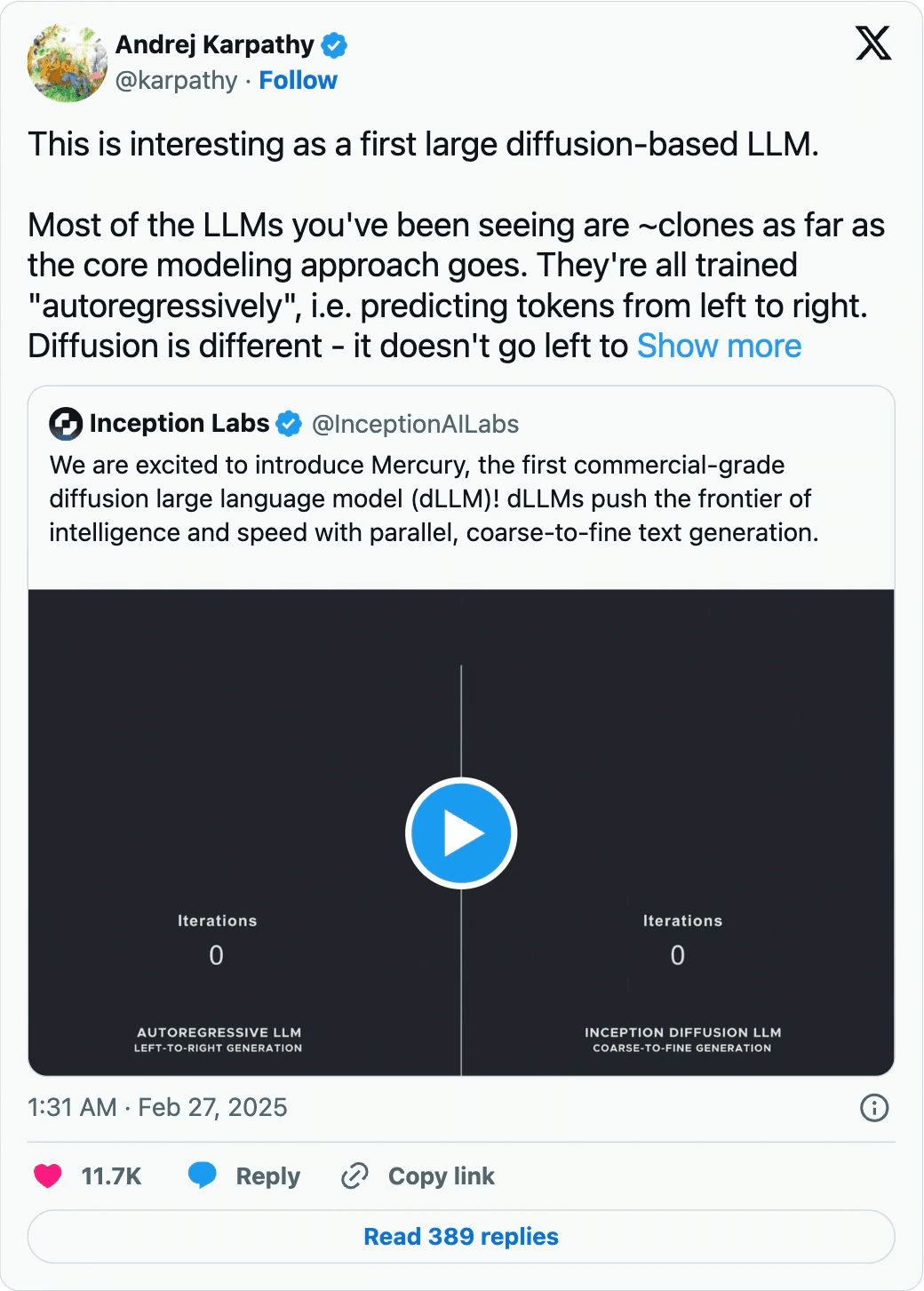
No! These models are themselves speeding up over time, and there are lots of ideas on how to continue this. It will be interesting to see how these different techniques will also wield different types of output, and how they can be used for different use cases.
It’s fascinating how image generation has explored the other direction too, such as with the excellent new OpenAI image gen model. With that zig, we now see the zag with text.
And, researchers are already investigating hybrid models that combine autoregressive and diffusion techniques. For example, an Auto-Regressive Diffusion model (AR-Diffusion) has been proposed, which tries to blend the sequential consistency of AR with the parallelism of diffusion. Such models might generate in a diffusion manner but use an AR-like decoder or vice versa, aiming to get “the best of both worlds.”
What a time to be alive as an AI Native Dev!




