OpenAI has finally done it: after months of promises, the ChatGPT hitmaker has released its first open-weight large language models (LLMs) since GPT-2 some six years ago.
The launch follows long-standing criticism over its abandonment of its original “open” AI ethos. Co-founder Elon Musk has been among the most vocal detractors, going so far to sue OpenAI, alleging “deceit of Shakespearean proportions.” Others in the community have likewise lamented the company’s shift toward secrecy and commercial control.
Sasha Luccioni, a research scientist at Hugging Face, argued in 2023 that withholding model details undermines broader scientific progress. “All of these closed-source models – they are essentially dead-ends in science,” Luccioni said. “They [OpenAI] can keep building upon their research, but for the community at large, it’s a dead end.”
In the intervening years, OpenAI has also faced growing pressure from more “open”-aligned rivals such as Meta and China’s DeepSeek, which have demonstrated the competitive benefit of releasing powerful models under permissive licenses. Earlier this year, OpenAI CEO Sam Altman conceded that his company could be “on the wrong side of history” regarding open source.
And so this brings us to its new LLM series dubbed gpt-oss, which OpenAI says will “push the frontier of open-weight reasoning models.”
In reality, gpt-oss could be OpenAI’s effort at ingratiating itself with the scientific, research, and developer communities once more.
Available under an Apache 2.0 licence, gpt-oss-20b is a lightweight reasoning model for lower latency or local deployment. With 21 billion parameters and a 16 GB memory footprint, it’s compact enough to run on personal computers, edge devices, or in research and other resource-constrained environments.
The gpt-oss-120b model, meanwhile, is built for general purpose, production use-cases, though it’s small enough to fit on a single 80GB GPU, making it suitable for on-premises deployment without requiring large multi-GPU clusters.
Both models use a mixture-of-experts (MoE) architecture, which activates only a small subset of parameters for each inference. In practice, that means just a handful of specialized “experts” are engaged at a time, cutting compute costs and latency while preserving the broad knowledge and capabilities of a larger model.
For context, OpenAI also debuted its flagship GPT-5 LLM this week. While the company hasn’t disclosed its parameter count, estimates put the figure at somewhere in the “many trillions,” making it far less practical for smaller-scale projects or experimental setups.
The new gpt-oss series, by contrast, is still fairly capable and competitive with OpenAI’s smaller proprietary models (e.g. o4-mini / o3-mini), but it’s not state-of-the-art in the same way as GPT-5 is. It’s mostly about giving developers, researchers, and companies the ability to run models locally, fine-tune and adapt them for specific domains, and experiment with architecture without starting from scratch.
So, how does gpt-oss actually perform in real-world scenarios? Well, the data isn’t yet available on SWE-Bench, the LLM industry’s go-to benchmark for automated software engineering tasks, so it’s a case of “watch this space” in terms of independent verification.
However, OpenAI provides its own benchmarking data in the gpt-oss model card, which (if taken at face value) suggests that gpt-oss-20b and gpt-oss-120b are capable performers in their weight class, but not designed to challenge the very top frontier models.
On MMLU (a broad general-knowledge and reasoning test), gpt-oss-20b scores 72.6% and gpt-oss-120b 78.5%, the latter essentially matching OpenAI’s own o3-mini. In SWE-Bench Verified (a human-validated subset of SWE-Bench built from real GitHub issues), the 20b model achieves 23.4% Pass@1 (task solved at first attempt), while the 120b model reaches 30.8%, placing them within the performance range of other competitive open-weight code models in their size class.
Taken together, these results put both models in a strong position within their respective size classes, though neither is intended to compete with top frontier systems like GPT-5 or Claude 4.
Initial feedback, though mixed, has leaned more toward the positive end of the spectrum, with users keen to put gpt-oss-20b, in particular, through its paces to see what it’s made of.
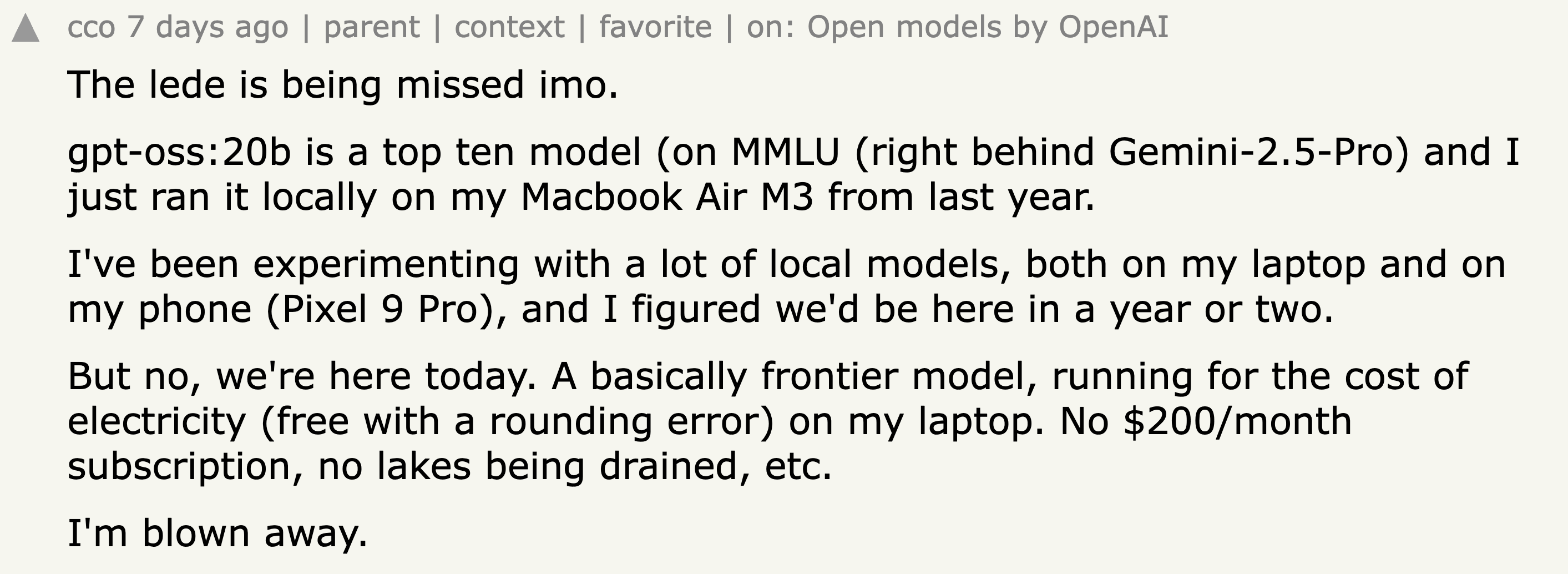
This was evident on Hacker News, with one early tester struck by how capable gpt-oss-20b is, calling it a near-frontier model that runs smoothly on everyday hardware.
“I've been experimenting with a lot of local models, both on my laptop and on my phone (Pixel 9 Pro), and I figured we'd be here in a year or two,” the user noted. “But no, we're here today. A basically frontier model, running for the cost of electricity…”
Another tester said that gpt-oss-20b was the smallest model they’d encountered that could reliably solve the classic wolf–goat–cabbage puzzle (a multi-step river crossing logic test) in high reasoning mode, without special prompting.

Not everyone was convinced, though, with one tester noting that gpt-oss-20b failed the simple river-crossing puzzle with the item labels changed, a variation that other local models, like QwQ-32B, could solve.
Another commenter countered that the 20b’s 4/32 MoE design means only ~3.6b parameters are active at a time, so it’s unsurprising it might trail a larger dense model on certain tasks, yet still be considered state-of-the-art within its efficiency-focused scale.

Overall, early reactions show a model that can both impress and disappoint, handling some tasks with ease while stumbling on others, albeit entirely within its size and design limitations.
How useful gpt-oss-20b proves in practice will depend on how it holds up under wider, longer-term testing.
A debate that often causes consternation in the software development community is the use of the term “open source” to describe software that isn’t open source as per the official open source initiative (OSI) definition.
With the advent of AI, the waters muddy even further, given the difficulty of transposing a licensing paradigm from traditional software over to machine learning models and their associated training data.
With that in mind, OpenAI is specifically calling these new models “open weight” as opposed to “open source,” avoiding the inevitable backlash that Meta attracted by calling its Llama models “open source.”
Both gpt-oss-120b and gpt-oss-20b are available under an Apache 2.0 licence, but that only refers to the model weights (i.e. the trained numerical parameters that define the model’s behavior) and architecture, which are free to use, modify, and distribute.
So while the gpt-oss model weights are very much open, the full training data, code, and processes behind them, aren’t. This means you can build on what OpenAI has released, but you can’t fully retrace or reproduce how these models were trained from scratch.
This distinction has already generated significant debate in the online community, with some questioning how OpenAI can have an Apache 2.0 license, but not meet the definition of “open source.”
In general, the consensus seemed to suggest that OpenAI’s leaning into “open weight” is the correct approach, given the clear “unsuitability of the term ‘open source’, and some open source licenses, to AI models,” as one Reddit user noted.
Some in the science and research community may care about such distinctions, since recreating a model requires full access to data and training code. This is important for auditing data, verifying results, or otherwise studying its training process.
But for most developers, being able to run, fine-tune, and deploy is really all that matters.
In many ways, OpenAI had little choice but to re-embrace its open roots. In 2025 so far, the LLM landscape has been decisively shaped by high-performance, open-weight models emanating from China, led by DeepSeek with its breakthrough R1 model, with the likes of Alibaba’s Qwen 2.5‑Max and Moonshot AI’s Kimi K2 in hot pursuit.
This shift has real practical consequences for developers the world over. Beyond the symbolism of “greater transparency,” these releases make it easier to adapt models for specific tasks and run them outside the control of a single vendor. And as the technology improves, such models are becoming more capable of supporting “agentic” setups, where AI systems break down goals, carry out multi-step processes, and interact with tools without constant human input. Open licensing also means they can be fine-tuned for specialist domains, integrated into existing infrastructure, and deployed on-premises far easier than closed, API-centric systems.
And so for OpenAI to remain competitive, it really had to put viable open-weight models back on the table.




