18 Dec 202510 minute read

18 Dec 202510 minute read
Letta, a generative AI startup that spun out of Berkeley's AI research lab in 2024, has launched Letta Code, a command-line-based open source coding agent designed around a simple premise: coding assistants should remember what they’ve learned.
Context engineering is emerging as a distinct discipline as AI systems move beyond single prompts and into longer-running, agent-driven tasks. Rather than resetting context on each interaction, the focus is increasingly on how information is retained, structured, and reused over time — and how that shapes reliability and behavior.
Letta Code, for its part, is built to “persist” context over time, allowing agents to accumulate knowledge about a developer, their team, and their codebase. As well as its open source credentials, a key pitch behind the coding agent is that it’s model-agnostic, meaning it can run atop various large language models (LLMs), rather than being tied to a single provider.
Letta positions this combination of openness, model flexibility, and long-lived memory as a counterpoint to the countless closed coding agents that dominate the current landscape, such as Anthropic’s Claude Code or OpenAI’s Codex.
Many of the popular coding CLIs today follow a stateless pattern: a developer invokes an agent, completes a task, and the session ends. When the next task begins, the agent starts from scratch.
Letta Code professes a different approach.
“In Claude Code – and every other coding CLI – every time you want to work on a task, you type `claude` (or `codex`, etc), and spin up a new ‘agent’,” Letta co-founder and CEO Charles Packer noted on LinkedIn. “The agent is brand new - it doesn't know anything about you, and has [no] real history of prior interactions. In contrast, Letta Code is fully stateful. The idea is that you work with a small handful of agents that get better and better over time as they learn more about you and your codebase.”
Packer likens the approach to working with human collaborators, where feedback accumulates over time and past mistakes inform future decisions.
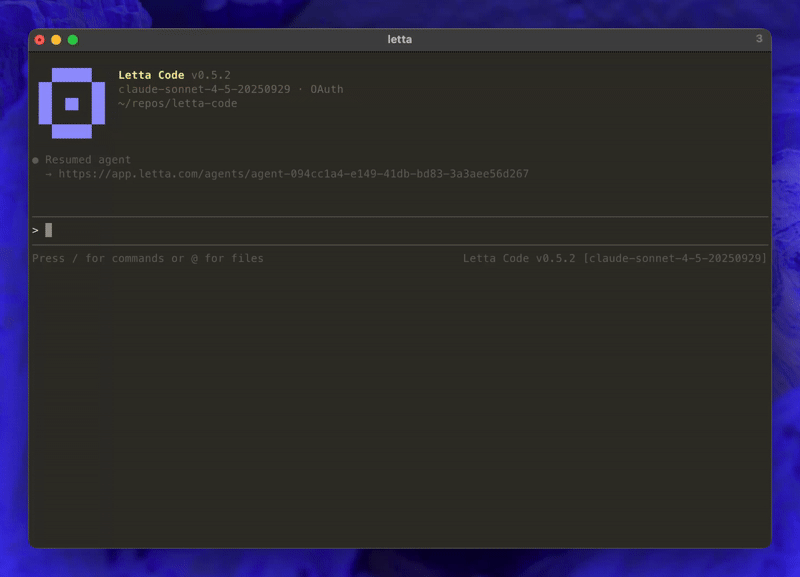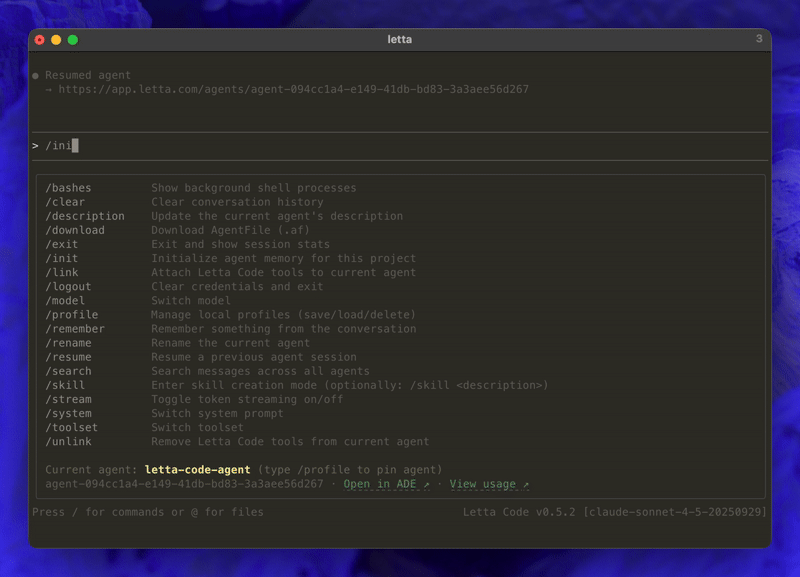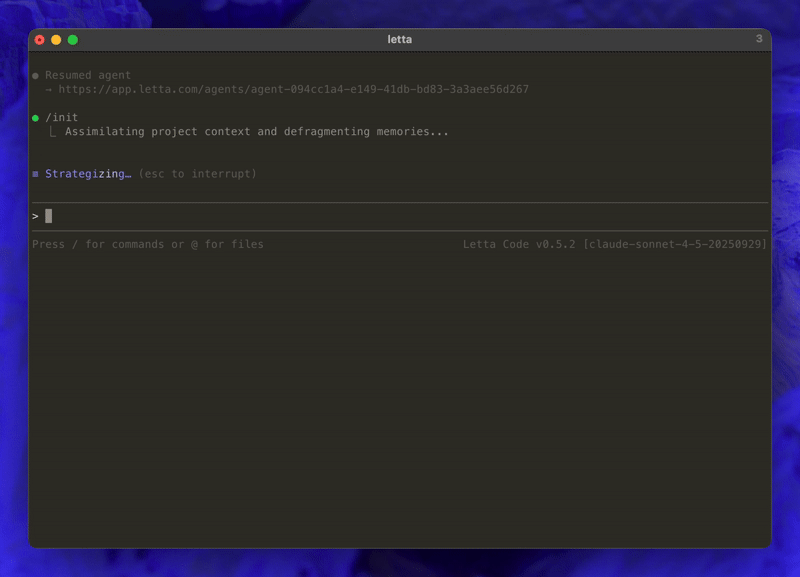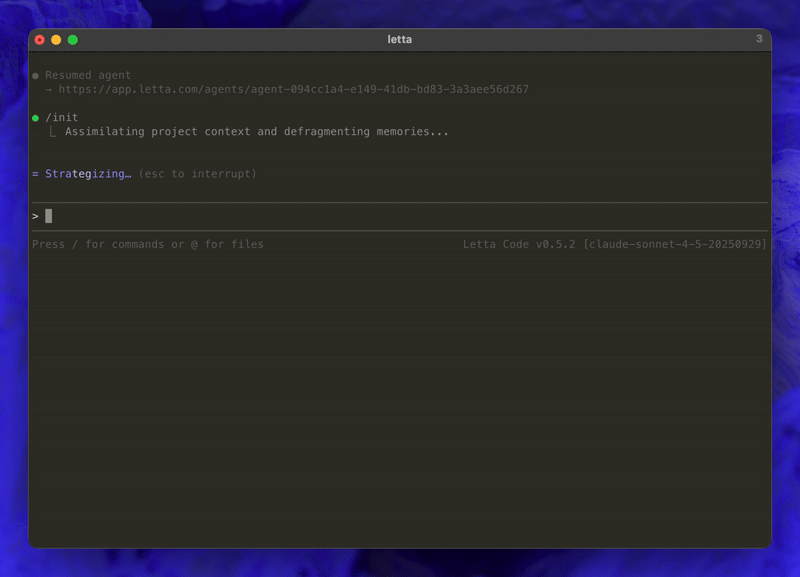
In Letta Code, developers work with a small number of persistent agents that retain memory across sessions. Those agents can be explicitly taught through commands such as /init, which prompts the agent to perform deeper research across a repository, and /remember, which allows users to correct mistakes and guide future behavior. Over time, those corrections become part of the agent’s working knowledge.
While positioned primarily as a coding tool, Letta Code is also pitched as a general-purpose agent harness built on top of Letta’s broader developer platform, which is designed for creating and running long-lived, stateful agents. Through the CLI, developers can connect any Letta agent — coding or otherwise — to a local machine, granting it controlled access to files, programs, and developer tooling. In that sense, coding is just one use case for a broader agent runtime that treats the terminal as an interface rather than the endpoint.
“For example, if you have a personal assistant agent running on a remote Letta server, you can use the Letta Code CLI to ‘beam’ that agent down into your terminal to give it access to your computer (and all your files / programs),” Packer noted.
At the same time, Packer tacitly acknowledges the growing number of AI coding tools competing for developer attention. Rather than introducing an entirely new interaction model, Letta has opted to keep the interface intentionally familiar, lowering the barrier for developers already accustomed to agent-driven CLIs.
“If you're a Claude Code user, the Letta Code interface should be instantly familiar,” Packer said.
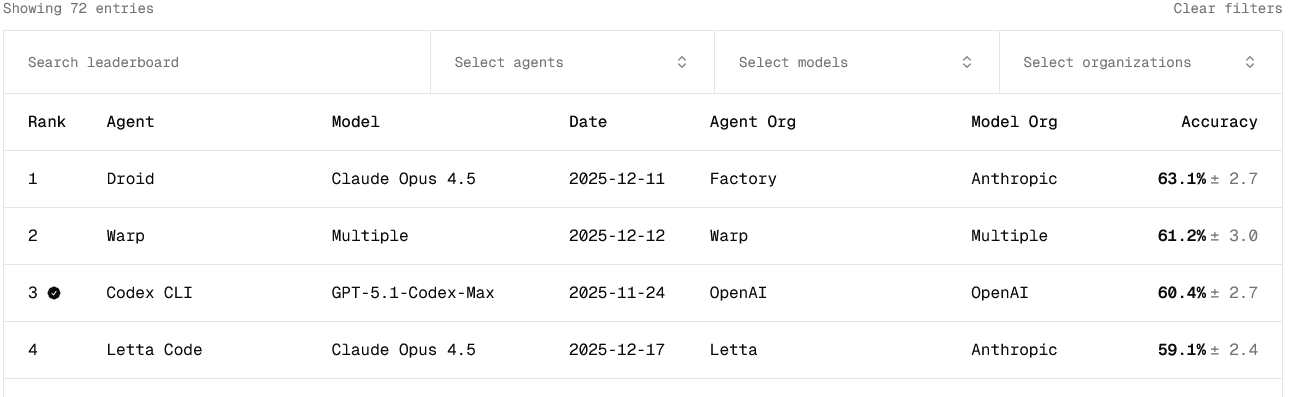
It’s still early days for Letta Code, but reaction and traction so far has been fairly positive. On Terminal-Bench, the emerging de facto standard for benchmarking AI coding agents in the command-line, Letta Code sits in fourth spot at the time of writing.
But Letta is quick to stress that in the model-agnostic, open source category, specifically, Letta Code is actually in pole position.
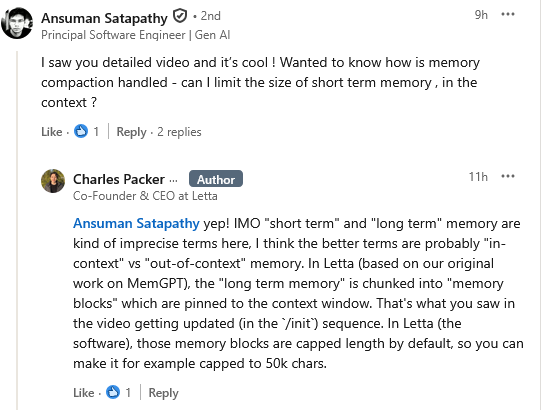
Given that “memory” is among Letta Code’s core USPs, one online commenter asked how memory compaction — that is, how an agent decides what information to retain in its active context — is handled, and whether developers can place limits on how much short-term memory is kept inside the model’s context window. The question touches on a practical concern with stateful agents: as memory accumulates, teams need mechanisms to control what remains immediately accessible and how large that working context can grow.
In response, Packer pushed back on the terminology itself, arguing that “short-term” and “long-term” memory are imprecise labels. Instead, he described Letta’s approach in terms of in-context versus out-of-context memory. Building on their earlier MemGPT research out of Berkeley, Packer explained that what is often described as long-term memory is stored as discrete memory blocks that are selectively pinned into the model’s context window. Those blocks, he added, are capped in size by default — for example, to a fixed character limit — allowing developers to constrain how much memory is surfaced at any given time.
Elsewhere, one curious commenter asked why Letta Code looks so much like Claude Code. Packer responded that this design choice was “very intentional,” reflecting an effort to avoid competing at the interface level and instead keep the focus on deeper architectural differences.
“We're heavy users [and] big fans of Claude Code at Letta, and we're not trying to innovate at the UI layer, we're innovating at the ‘memory’ (context engineering) layer,” Packer wrote. “So it helps to have the UI actually look quite similar, so you can focus on the real intended difference (the memory system in Letta being better than in Claude Code).”
The emphasis on long-term memory, while important, raises practical questions about how that memory is managed. Persistent context can be powerful, but it also introduces new challenges around verification, maintenance, and collaboration. Memories may need to be reviewed, shared across teams, or updated as systems evolve and assumptions change.
That tension is beginning to surface across the ecosystem. Platforms like Tessl, for example, are exploring how structured context and shared knowledge can be treated as first-class artifacts, with their own lifecycle and governance.
From that perspective, Letta Code highlights both the promise and the complexity of memory-driven development: remembering is useful, but deciding what should be remembered — and for how long — becomes a new layer of engineering work.
It’s also worth noting that Letta is not alone in pushing toward more open, model-agnostic coding agents. There’s Kilo Code, for starters, which is also pitched as an open source, model-agnostic coding agent that sits above the model layer versus locked to a single provider.
But together, these efforts point to a broader shift away from monolithic, vendor-bound assistants and toward agent architectures where tooling, context management, and execution strategy increasingly matter as much as the underlying model.
As coding agents take on longer-running roles, tools like Letta Code and its ilk highlight a shift away from disposable, session-based assistants toward more durable software collaborators. Whether that model scales cleanly may depend less on how powerful individual models become, and more on how well teams learn to manage memory, context, and agency over time.



