5 Jan 202610 minute read

5 Jan 202610 minute read
Large language models (LLMs) are getting bigger, but most developers still have to work within tight limits on speed, cost, and hardware. MiniMax M2.1, released on December 23, is an attempt to square that circle: a large model that behaves more like a much smaller one at inference time.
The new model is the handiwork of MiniMax, a Beijing-based AI company founded in 2022, which counts Tencent and Alibaba among its backers and is reportedly preparing to file for a Hong Kong IPO that could raise around US$500 million.
While MiniMax is perhaps less well-known among Western developers than other foundation model labs, the company has been steadily publishing large-scale models over the past year, with an emphasis on making model weights publicly available under open licenses. MiniMax M2.1 continues on that trajectory.
Back in June, MiniMax introduced MiniMax-M1, positioned as a general-purpose foundation model and an early signal of its interest in releasing large models with publicly available weights. That was followed by MiniMax-M2 in October, which increased overall scale and marked MiniMax’s first serious push into mixture-of-experts (MoE) architectures — setting the stage for the efficiency-focused updates that arrive with M2.1.
The emphasis, now, is on improving practical performance and broadening the model’s usefulness for real development work.
“In M2, we primarily addressed issues of model cost and model accessibility,” the company wrote. “In M2.1, we are committed to improving performance in real-world complex tasks: focusing particularly on usability across more programming languages and office scenarios, and achieving the best level in this domain.”
As with its predecessor, the MiniMax M2.1 is based on a MoE architecture. That means the model contains a very large pool of parameters — more than 200 billion in total, placing it toward the higher end of the open-weight model spectrum.
As per data from Artificial Analysis, an independent AI benchmarking and insights firm, MiniMax M2.1 follows the same sparse design pattern as its predecessor, with roughly 10 billion parameters active at inference time, consistent with the profile MiniMax disclosed for M2. This means the model only activates a small part of itself for each request, rather than running the entire system every time — which helps keep response times and serving costs closer to those of much smaller models.
MiniMax, for its part, frames the M2.1 iteration more as an improvement in how the existing architecture performs, particularly in terms of responsiveness, reliability, and token efficiency during real development workflows.
“In practical programming and interaction experiences, response speed has significantly improved and token consumption has notably decreased, resulting in smoother and more efficient performance in AI Coding and Agent-driven continuous workflows,” the company said.
That emphasis on practical, day-to-day usage also shows up in where MiniMax has focused its optimization efforts — particularly around programming languages.

Rather than treating non-Python languages as an afterthought, MiniMax positions M2.1 around the mix of languages and runtimes developers encounter in production systems – an emphasis that aligns with a broader shift in how developers are evaluating large models.
“We’re watching a shift: ‘largest model wins’ → ‘most usable model wins,’” software engineer Raul Junco wrote on LinkedIn. “MiniMax M2.1 is a clean example of that change.”
Instead of optimizing primarily for headline model size or abstract benchmarks, Junco suggests that M2.1 reflects a focus on “actual developer work,” including the ability to move comfortably across multiple programming environments.
Indeed, MiniMax M2.1 includes experts optimized for Java, Go, Rust, C++, TypeScript, JavaScript, and Kotlin, alongside Python. For full-stack developers working across backend services, frontend applications, and systems code, that breadth can matter more than marginal gains in a single language.
“Many models in the past primarily focused on Python optimization, but real-world systems are often the result of multi-language collaboration,” MiniMax said in its announcement.
Alongside the new model launch, MiniMax published a set of benchmarks positioning M2.1 as a step up from M2 on applied coding and agent-style tasks. For example, on SWE-bench Verified, which evaluates a model’s ability to resolve real GitHub issues end to end, M2.1 scores higher than MiniMax-M2 and moves closer to the range occupied by strong proprietary systems such as Claude Sonnet 4.5, Gemini 2.5 Pro, and GPT-5 (thinking), even though it still trails those leaders.
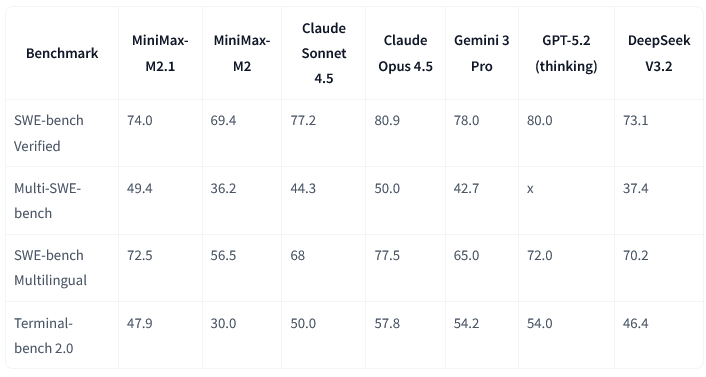
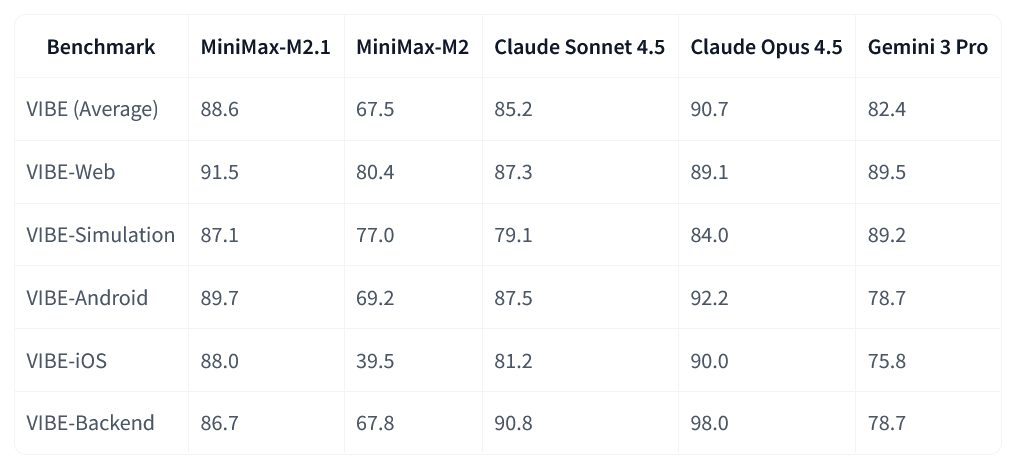
To evaluate application development beyond isolated coding tasks, MiniMax has also developed VIBE (Visual & Interactive Benchmark for Execution in Application Development), an internally constructed benchmark covering web, mobile, simulation, and backend scenarios.
On VIBE, M2.1 shows a substantial improvement over MiniMax-M2 and performs competitively with large proprietary models across several categories. As a first-party benchmark, VIBE is best read as directional rather than definitive, but it reinforces MiniMax’s broader claim that M2.1 is optimized for full-stack development rather than narrow, single-language use cases.
Early community reactions have been mixed. Some developers testing M2.1 described it as one of the stronger options among open-weight models, particularly in agent-based setups, while others found it less reliable than leading proprietary systems for deeper debugging and code review. Much of the disagreement hinged on what the model was being compared against, and how it was being used.
“For coding, I did not like it very much,” one Reddit user wrote, after comparing M2.1 with GLM-4.7 and Claude Sonnet 4.5. “Both GLM and Sonnet gave me great code, but MiniMax 2.1 was like a junior software engineer.”
Elsewhere, another commenter said that MiniMax M2.1 was “currently the best for agentic coding and stuff,” prompting another user to retort: “Not even close. Claude Sonnet 4.5 without thinking is much better than MiniMax; at least the tests i've done showed that MiniMax 2.1 is more like a junior SWE, and Claude a specialist.”
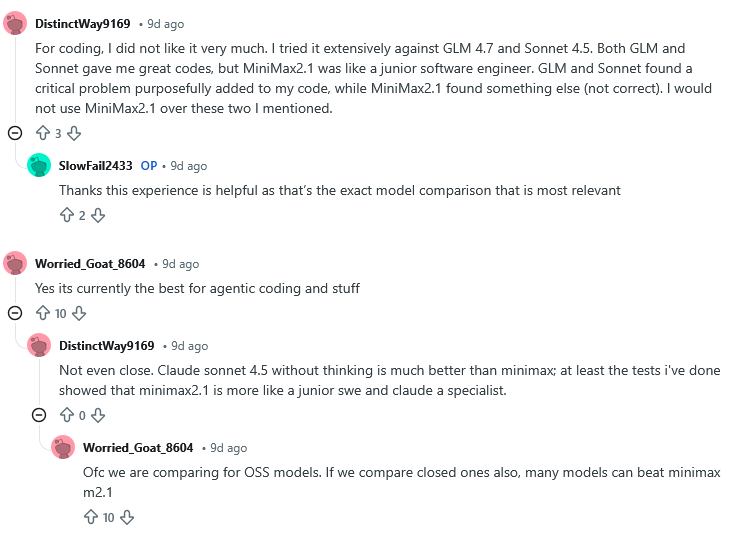
The mixed reactions highlight how MiniMax M2.1’s perceived strengths depend heavily on context — particularly whether it is evaluated against other open-weight models or against highly optimized proprietary systems, and which kinds of coding tasks are being emphasized.
MiniMax has made M2.1 available through several official channels, including the company’s own API via the MiniMax Open Platform, and through MiniMax Agent, a first-party agent product built directly on top of M2.1.
In addition, MiniMax has published the model’s weights on Hugging Face, allowing teams with sufficient infrastructure to deploy it locally. In practice, however, models of this size still require multi-GPU, server-class hardware to run locally, putting true self-hosting out of reach for most developers working with consumer-grade GPUs.
The good news is that MiniMax’s API pricing makes practical usage fairly accessible, with M2.1 priced at around $0.30 per million input tokens and $1.20 per million output tokens, with a “lightning” variant available at higher output cost for faster throughput.
Elsewhere, MiniMax M2.1 is also beginning to appear inside third-party developer tools. Kilo Code, for instance, has just announced that M2.1 is free for a “limited time” inside its terminal-based coding agent. OpenCode has likewise surfaced the model through Zen, its curated model catalogue used to power OpenCode’s coding agent.
In these cases, MiniMax M2.1 is hosted and served by the tool providers themselves rather than run locally, giving developers a low-friction way to try the model without managing infrastructure or setting up a direct API integration.




